WebScrapBook (oegnpmiddfljlloiklpkeelagaeejfai): Capture web pages to local device or backend server for future retrieval, organization, annotation, and editing.... Read More > or Download Now >
WebScrapBook for Chrome
Tech Specs
User Reviews

- • Rating Average
- 3.65 out of 5
- • Rating Users
- 75
Download Count
- • Total Downloads
- 990
- • Current Version Downloads
- 0
- • Updated: April 6, 2024
WebScrapBook is a free Productivity Extension for Chrome. You could download the latest version crx file or old version crx files and install it.
More About WebScrapBook
***This extension is under development. Every feature could change in the future. Use in production carefully and be sure to make a backup frqeuently.***
WebScrapBook is a browser extension that captures the web page with highly customizable configurations. This project inherits from legacy Firefox addon ScrapBook X.
Features:
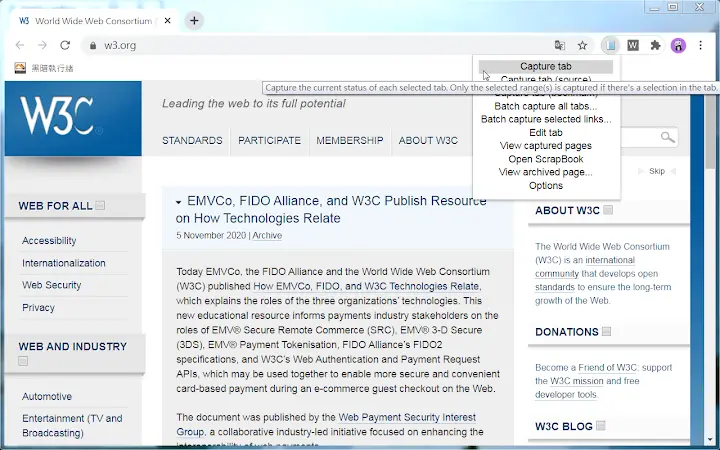
1. Capture web pages faithfully: Web pages shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a zip-based archive file (HTZ or MAFF), or a single HTML file.
3. Management of captured pages: Captures can be organized in the browser sidebar using one or more "scrapbooks", which holds a hierarchical tree structure to represent the relationship between each captured data item. Each scrapbook can be further indexed for a rich-feature search (using a combination of fulltext keywords, title, custom comment, source URL, or other metadata). (*)
4. Page editing: A web page can be edited before performing a capture. A captured page can be edited and saved back to the system. You can additionally create and manage note pages in HTML or markdown format. (*)
6. Access everywhere: Captured pages can be hosted with a central backend server so that you can access your scrapbooks from multiple devices. A static index can also be generated for a scrapbook, which can therefore be hosted on almost any shared server. (*)
7. Import from legacy ScrapBook: Data collected using legacy ScrapBook can be imported into WebScrapBook for later usage.
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, with PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki: https://github.com/danny0838/webscrapbook/wiki.
* For further information and frequently asked questions, visit the documentation wiki: https://github.com/danny0838/webscrapbook/wiki/Intro
WebScrapBook is a browser extension that captures the web page with highly customizable configurations. This project inherits from legacy Firefox addon ScrapBook X.
Features:
1. Capture web pages faithfully: Web pages shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a zip-based archive file (HTZ or MAFF), or a single HTML file.
3. Management of captured pages: Captures can be organized in the browser sidebar using one or more "scrapbooks", which holds a hierarchical tree structure to represent the relationship between each captured data item. Each scrapbook can be further indexed for a rich-feature search (using a combination of fulltext keywords, title, custom comment, source URL, or other metadata). (*)
4. Page editing: A web page can be edited before performing a capture. A captured page can be edited and saved back to the system. You can additionally create and manage note pages in HTML or markdown format. (*)
6. Access everywhere: Captured pages can be hosted with a central backend server so that you can access your scrapbooks from multiple devices. A static index can also be generated for a scrapbook, which can therefore be hosted on almost any shared server. (*)
7. Import from legacy ScrapBook: Data collected using legacy ScrapBook can be imported into WebScrapBook for later usage.
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, with PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki: https://github.com/danny0838/webscrapbook/wiki.
* For further information and frequently asked questions, visit the documentation wiki: https://github.com/danny0838/webscrapbook/wiki/Intro
![]()